[AI] 가중치는 그대로, 스킬만 훈련한다 - Microsoft SkillOpt를 읽고
Microsoft Research에서 나온 SkillOpt라는 프로젝트를 봤다. (arXiv:2605.23904, GitHub)
처음엔 “또 프롬프트 자동 튜닝 도구겠거니” 하고 열었는데, README 첫 줄을 보고 멈췄다.
“Train agent skills like you train neural networks — with epochs, (mini-)batchsize, learning rates, and validation gates — but without touching model weights.”
신경망을 훈련하듯 에이전트의 “스킬”을 훈련한다. 다만 모델 가중치는 건드리지 않는다. 이 한 문장이 묘하게 마음에 걸려서, 읽으면서 든 생각을 정리해보려고 한다. 늘 그렇듯 논문을 그대로 옮기기보다, 내가 평소에 하던 일과 겹치는 지점 위주로 적는다.
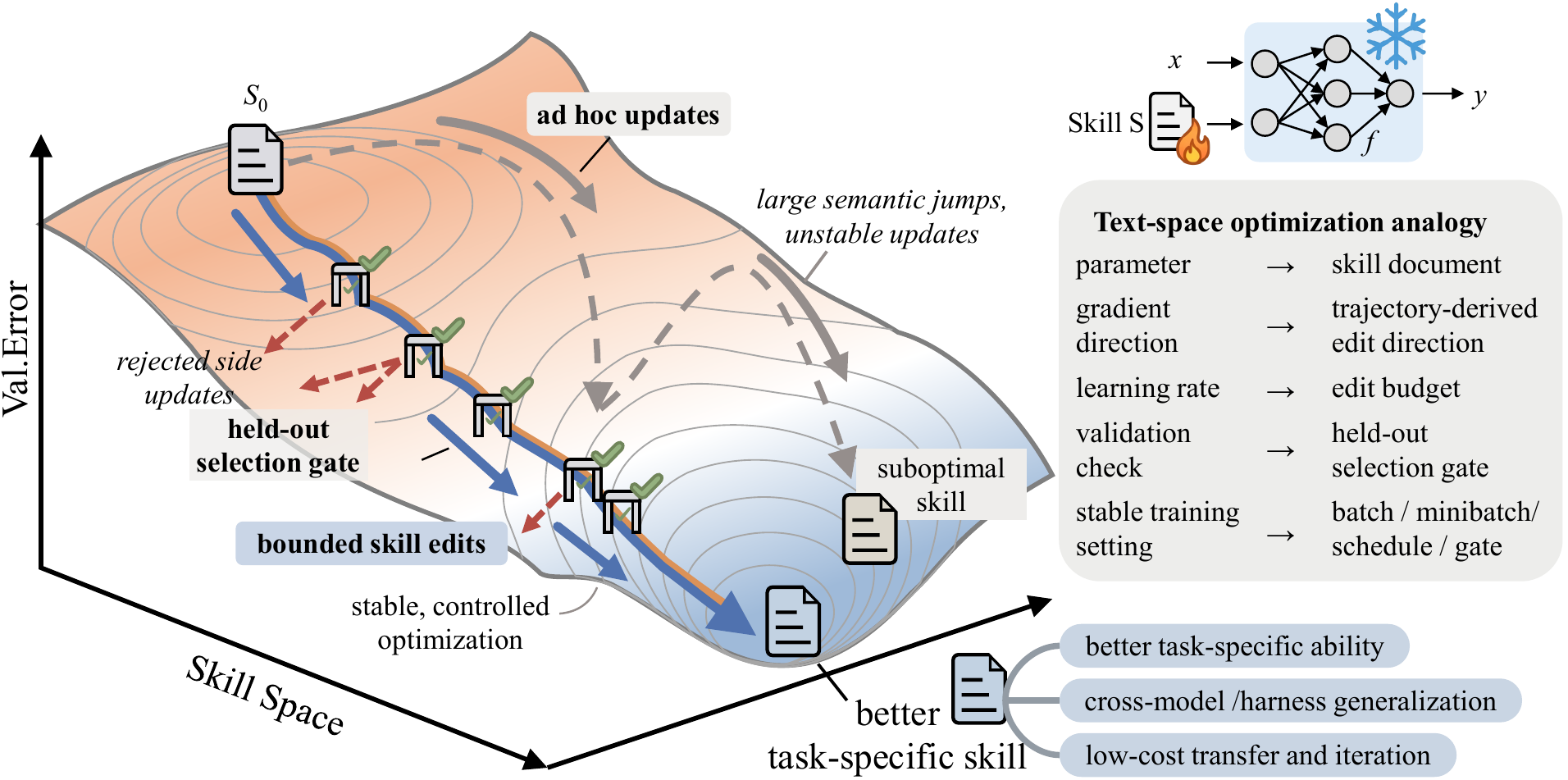 손실 곡면 위에서 가중치 대신 “스킬 문서”를 최적화한다. 오른쪽 표는 신경망 훈련 개념과의 대응(parameter→skill document, learning rate→edit budget, validation→held-out gate)이다. (출처: SkillOpt, Microsoft Research, arXiv:2605.23904)
손실 곡면 위에서 가중치 대신 “스킬 문서”를 최적화한다. 오른쪽 표는 신경망 훈련 개념과의 대응(parameter→skill document, learning rate→edit budget, validation→held-out gate)이다. (출처: SkillOpt, Microsoft Research, arXiv:2605.23904)
SkillOpt가 푸는 문제
요즘 에이전트를 좋게 만드는 방법은 크게 두 갈래다.
하나는 모델 자체를 파인튜닝하는 것이다. 성능은 확실히 올릴 수 있지만 비싸고, 데이터도 많이 필요하고, 한 번 튜닝하면 다른 모델로 옮기기도 어렵다.
다른 하나는 프롬프트나 스킬 문서를 사람이 손으로 다듬는 것이다. 나도 매일 하는 일이다. Claude Code의 CLAUDE.md나 스킬 문서를 고치면서, “이건 이렇게 하지 마라”, “이 경우엔 저 파일을 먼저 봐라” 같은 규칙을 계속 손으로 추가한다.
문제는 이 손작업이 주먹구구라는 거다. 뭘 고쳤더니 한 케이스는 좋아졌는데 다른 케이스가 망가지고, 그걸 매번 사람이 눈으로 확인한다. 체계도 없고, 기록도 안 남고, 개선됐는지 나빠졌는지 객관적으로 알기 어렵다.
SkillOpt는 이 두 번째 갈래, 즉 “자연어 스킬 문서를 고치는 일”을 훈련 루프처럼 자동화하자는 시도다. 모델 가중치는 동결(frozen)해 두고, 오직 스킬 문서만 최적화 대상으로 삼는다.
핵심: 절차(스킬)를 훈련한다
README에 적힌 전체 루프는 이렇다.
rollout → reflect → aggregate → select → update → evaluate
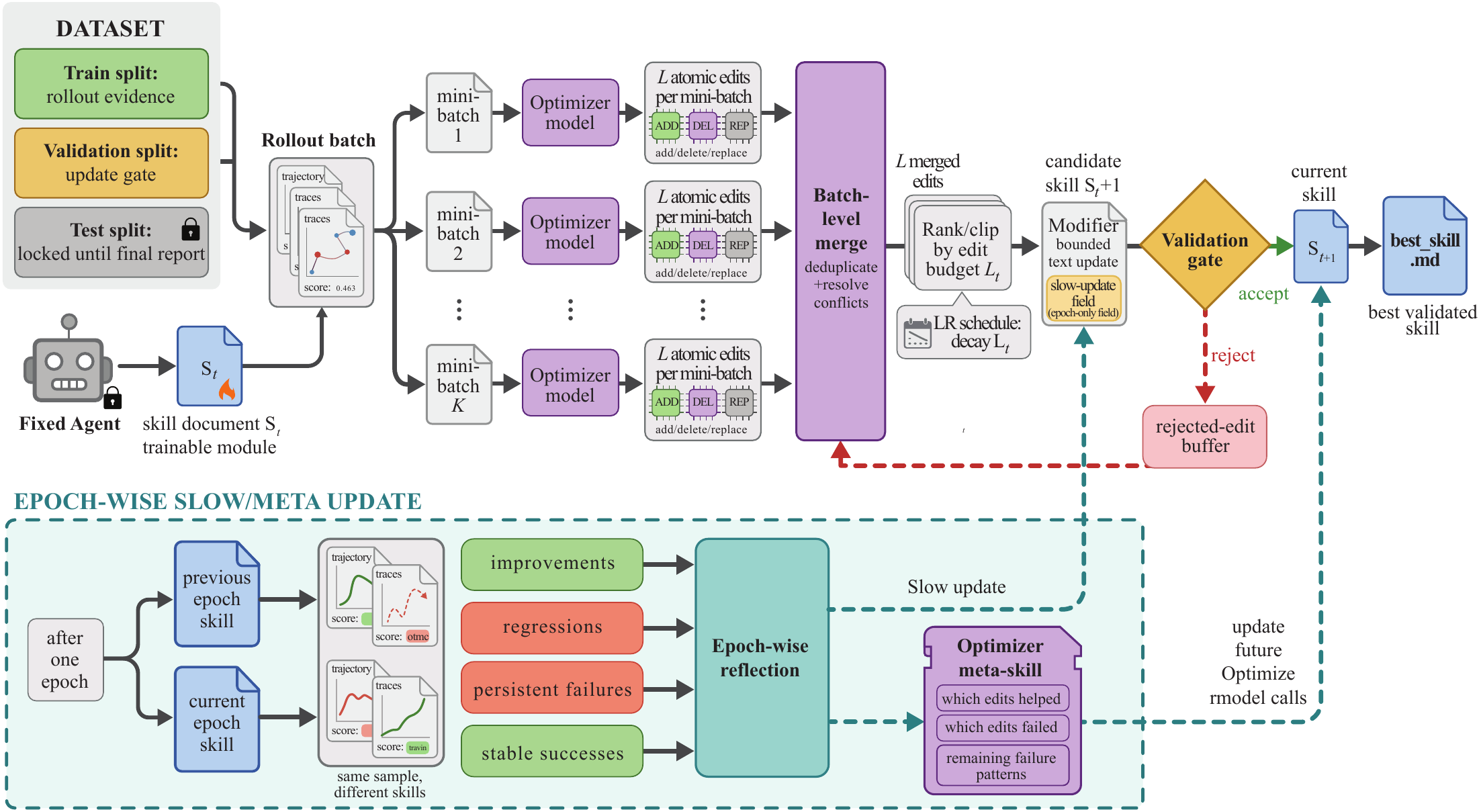 데이터를 train/validation/test로 나누고, rollout으로 모은 증거를 옵티마이저가 반성·편집한 뒤, validation gate를 통과한 것만 채택한다. 동결된(❄️) 모델은 그대로고, 바뀌는 건 스킬 문서뿐이다. (출처: SkillOpt, Microsoft Research)
데이터를 train/validation/test로 나누고, rollout으로 모은 증거를 옵티마이저가 반성·편집한 뒤, validation gate를 통과한 것만 채택한다. 동결된(❄️) 모델은 그대로고, 바뀌는 건 스킬 문서뿐이다. (출처: SkillOpt, Microsoft Research)
내 방식으로 풀어보면 이런 흐름이다.
- rollout: 지금 스킬 문서를 가지고 실제 작업을 여러 번 돌려보고, 잘했는지 못했는지 점수가 매겨진 기록을 남긴다.
- reflect: 별도의 옵티마이저 모델이 성공한 케이스와 실패한 케이스를 들여다보고, 무엇이 문제였는지 반성한다.
- aggregate / select: 여러 반성에서 나온 편집 후보들을 모으고, 그중 쓸 만한 것을 고른다.
- update: 고른 편집을 스킬 문서에 반영한다.
- evaluate: 따로 떼어 둔 검증 작업에서 점수가 실제로 올랐는지 확인한다.
흥미로운 건 신경망 훈련 용어를 그대로 가져다 쓴다는 점이다. epoch이 있고, (미니)배치 크기가 있고, 학습률 같은 개념이 있고, 검증 게이트가 있다. 다만 README에서도 이건 어디까지나 비유로 설명하는 것이지, “rollout이 곧 순전파다” 같은 식으로 1:1 대응시키지는 않는다. 이 부분은 내가 처음 요약본을 봤을 때 과하게 단정했다가, 원문을 다시 확인하고 바로잡은 지점이기도 하다.
내가 가장 좋게 본 장치는 두 가지다.
제한된 편집(bounded edit). 한 번에 스킬 문서를 왕창 갈아엎지 못하게 편집 예산을 둔다. 이게 학습률 같은 역할을 한다. 안 그러면 잘 작동하던 규칙까지 같이 날아가니까. 손으로 프롬프트 고칠 때 내가 제일 자주 저지르는 실수가 바로 이거다. 한 번에 너무 많이 바꿔서, 뭐 때문에 좋아지고 나빠졌는지 알 수 없게 되는 것.
검증 게이트(gate). 새 스킬은 검증 점수가 실제로 올랐을 때만 채택된다. 반성해서 “이렇게 고치면 좋겠다”고 제안하는 것과, 그게 진짜 나은지는 다른 문제다. 게이트가 그 사이를 끊어준다. 반성을 그냥 믿는 게 아니라, 제안하고 → 테스트하고 → 통과해야 받는 구조다.
어? 내가 손으로 하던 게 이거네
여기까지 읽고 나서 든 생각은 단순했다. 이거 내가 매일 손으로 하던 일이잖아.
나는 Claude Code로 작업하면서 스킬 문서랑 CLAUDE.md를 계속 고친다. “이 경우엔 이렇게 해라”를 추가하고, 잘못 동작하면 규칙을 손본다. 며칠 전에도 야구 데이터 수집기에서 base2Before 컬럼을 불린으로 잘못 읽던 버그를 잡고, 그 교훈을 문서에 규칙으로 남겼다.
SkillOpt의 루프를 내 작업에 그대로 겹쳐보면 이렇게 대응된다.
| SkillOpt 단계 | 내가 손으로 하던 일 |
|---|---|
| rollout | 작업을 돌려보고 결과를 본다 |
| reflect | “아 이래서 틀렸구나” 하고 원인을 짚는다 |
| update | 문서에 규칙 한 줄 추가한다 |
| evaluate | 다음에 같은 작업을 시켜서 나아졌는지 본다 |
| gate | (없음) — “좋아진 것 같다”는 느낌으로 채택 |
즉 나는 이미 이 루프를 돌리고 있었다. 다만 전부 수동이고, 머릿속에 있고, 기록이 안 남는다는 것이 차이다. 그리고 표 마지막 줄, 검증 게이트가 통째로 비어 있다는 것도.
그래서 진짜 차이는 자동화와 검증 게이트다
논문이 한 일과 내가 하던 일의 차이를 좁히면 결국 두 가지다.
첫째, 반성과 편집을 사람이 아니라 옵티마이저 모델이 한다. 나는 매번 내가 직접 원인을 짚고 규칙을 쓴다. SkillOpt는 그걸 모델에게 시키고, 사람은 마지막에 채택만 한다(README의 SkillOpt-Sleep 흐름에서도 마지막 adopt는 사람 몫으로 둔다).
둘째, 검증 게이트가 있다. 나는 “이렇게 고치니 좋아진 것 같다”는 느낌으로 채택한다. 논문은 따로 떼어 둔 검증셋에서 점수가 오를 때만 채택한다. 이 차이가 생각보다 크다. 내 방식은 좋아진 기분에 속기 쉽고, 게이트가 있으면 그 자기기만이 걸러진다.
README에 적힌 수치로는, 예를 들어 GPT-5.5 기준으로 스킬 없는 상태 대비 평균 정확도가 일반 대화에서 +23.5, Codex 루프 안에서 +24.8, Claude Code 안에서 +19.1 올랐다고 한다. 테스트한 대상은 GPT-5.5, Claude, Codex, Qwen3.5-4B, MiniMax-M2.7 같은 모델들과 SearchQA, ALFWorld, DocVQA, SpreadsheetBench 등의 벤치마크다.
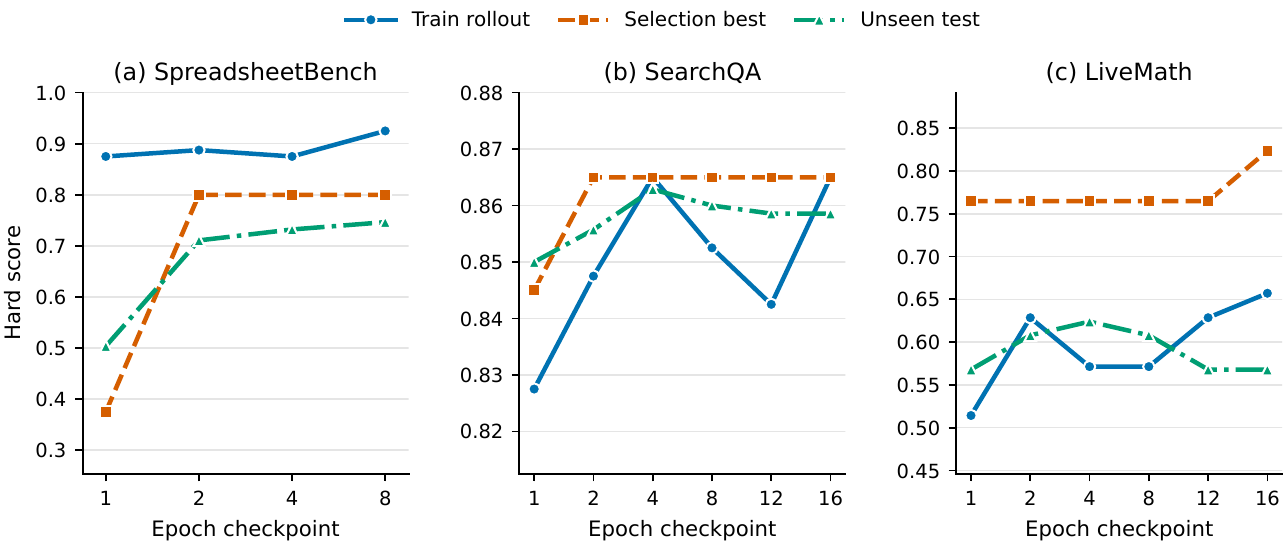 에포크가 돌수록 검증으로 고른 스킬(selection best, 주황)과 처음 보는 테스트(unseen test, 초록) 점수가 같이 오른다. 검증 게이트가 단순 암기가 아니라 일반화로 이어진다는 그림이다. (출처: SkillOpt, Microsoft Research)
에포크가 돌수록 검증으로 고른 스킬(selection best, 주황)과 처음 보는 테스트(unseen test, 초록) 점수가 같이 오른다. 검증 게이트가 단순 암기가 아니라 일반화로 이어진다는 그림이다. (출처: SkillOpt, Microsoft Research)
다만 이 숫자들은 어디까지나 논문이 자기 셋업에서 보고한 값이라는 점은 분명히 해두고 싶다. 나는 README와 프로젝트 페이지를 읽고 정리했을 뿐, 직접 재현해본 게 아니다. 그래서 “이만큼 오른다”가 아니라 “논문은 이만큼 올랐다고 보고한다” 정도로 받아들이고 있다.
내 작업에 가져온다면
당장 이걸 그대로 도입할 수 있느냐 하면, 솔직히 아니다. 검증셋을 만들고 옵티마이저 루프를 돌리는 건 그 자체로 일이다. 하지만 아이디어 두 개는 지금 당장 손으로라도 흉내 낼 수 있을 것 같다.
하나는 한 번에 조금만 고치기다. 스킬 문서를 손볼 때 왕창 갈아엎지 말고, 한 번에 규칙 하나씩만 바꾸고 결과를 본다. SkillOpt의 제한된 편집을 사람 버전으로 따라 하는 셈이다.
다른 하나는 검증 케이스를 미리 정해두기다. 지금은 “좋아진 것 같다”로 채택하는데, 자주 틀리던 케이스 몇 개를 고정해두고 거기서 나아졌을 때만 규칙을 남기는 식이다. 작게라도 게이트를 두는 것.
조금 더 멀리 보면, 내가 만들려는 것들에도 닿는다. 모델은 점점 좋아지고 가중치를 내가 건드릴 일은 거의 없다. 그러면 내가 손에 쥘 수 있는 건 결국 그 위에 얹는 스킬, 규칙, 절차 문서다. SkillOpt는 그 문서를 “관리하는 대상”이 아니라 “훈련하는 대상”으로 보라고 말한다. 관점 하나 바꾸는 것뿐인데, 내가 매일 주먹구구로 하던 일에 갑자기 이름과 구조가 생긴 느낌이었다.
며칠 전에 다른 글에서도 비슷한 생각을 했다. 코드를 짜는 일은 점점 싸지고, 남는 건 무엇을 어떻게 할지 아는 능력이라는 것. 스킬 문서를 훈련 가능한 자산으로 다루는 것도 결국 그 능력의 한 형태인 것 같다. 모델이 답을 더 잘 내게 만드는 게 아니라, 모델에게 줄 절차를 더 잘 설계하는 쪽으로.