AI / ML
- Alice
Machine learning
- 빅데이터를 분석, 이해, 예측
- 비정형데이터를 분석
- ai의 일부분, 데이터를 통계적으로 분석
- 통계학에서 다루는 데이터보다 훨씬 양이 많고, 노이즈도 많고, 데이터가 없거나 훼손된 부분도 많다
- 통계학의 한계 극복
Major Problem Formulations in ML
- Supervied Learning(지도학습)
- Unsupervied Learning(비지도학습)
- Reinforcement Learning(강화학습)
- Representation Learning
Supervied Learning(지도학습)
- 많은 사람들이 생각하는 ML
- 정답을 가지고 있는 학습 데이터(training)를 통해 새로운 데이터를 classification(분류)
- 선형모델 // 비선형모델
- 비선형모델
- Decision Trees
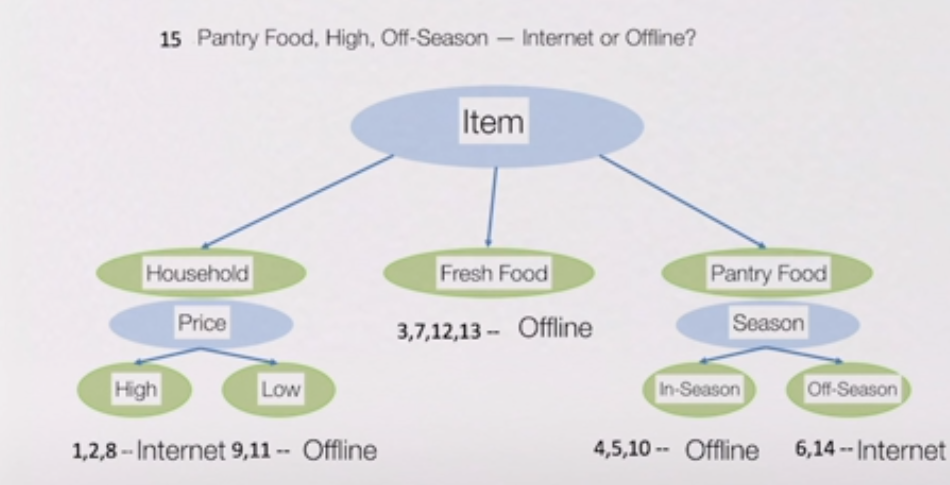
Unsupervied Learning
-
정답을 구하기 어려울 때
-
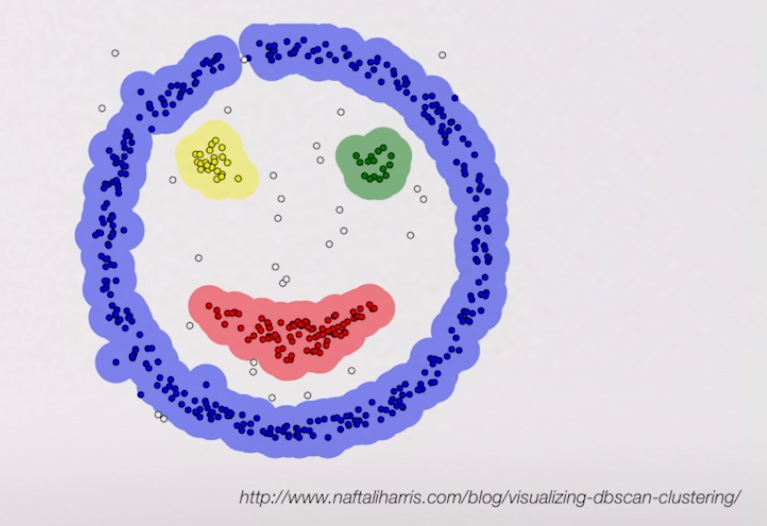
K-means clustering
- 데이터의 생김새에 따라 몇개의 그룹으로 나누어
- 기준이 되는 중간 점을 찾고, 거기에서 각각의 데이터 포인트의 거리를 계산해서 어떤 기준점에 가장 가까운 데이터인지를


-
DB scan
- 임의의 데이터 포인트 하나에서 시작해서 자기한테 가까운 점들을 묶어 늘려나가는 것
Representation Learning()
-
Deep Neural Network
-
Reducing the Dimensionality of Data with Neural Networks
- Facial recognition
- Layer 1 : 하나의 픽셀에 대해서 흑 / 백을 구분
- Layer 2 : 픽셀값을 연결해 경계선, 라인을 찾아냄
- Layer 3 : 선, 곡선의 조합으로 눈, 코 입등을 찾음
- Layer 4 : 위의 값으로 얼굴형 등을 좀더 자세하게 찾아냄

- Facial recognition
-
왜 사용되나?
- 모델의 표현력이 풍부하다
- 데이터량이 많아야하고, 메모리도 커야하고, 컴퓨터도 좋아햐 하는데 요즘에는 이런 조건들이 충족해져서 많이 사용
- 모델이 과적합하기 쉽다
- drop out
- 파라미터 측정이 어렵다
- 모델의 표현력이 풍부하다
Famous AI System
- IBM deep blue
- 자율주행
- IBM Watson
- Deep mind Alphago
- Google Duplex
- Visual Intelligence
- MNIST
- ImageNet
- Language Intelligence
- SQUAD Dataset
Linear Regression(선형회귀)
- 데이터에 대한 결과를 값, 즉 실수로
- x값이 주어졌을 때 y값을 예측

Numpy 배열
- 넘파이(Numpy)는 파이썬 기반의 고성능의 수치 계산을 위한 라이브러리
-
넘파이는 계산의 기반이 되는 배열(array)을 간편하게 생성할 수 있는 여러 가지 함수들을 제공하고 있다.
-
배열
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
from elice_utils import EliceUtils
import numpy as np
elice_utils = EliceUtils()
def main():
print("Array1: 파이썬 리스트로 만들어진 정수형 array")
array1 = np.array([1,2,3])
print("데이터:", array1)
print("array의 자료형:", type(array1))
print("dtype:", array1.dtype, "\n")
print("Array2: 파이썬 리스트로 만들어진 실수형 array")
array2 = np.array([1,2,3],dtype=float)
print("데이터:", array2)
print("dtype:", array2.dtype, "\n")
print("Array3: 0으로 10개 채워진 정수형 array")
array3 = np.zeros(10, dtype=int)
print("데이터:", array3)
print("dtype:", array3.dtype, "\n")
print("Array4: 1으로 채워진 3x5형태 실수형 array")
array4 = np.ones((1,3,5))
print("데이터:", array4)
print("dtype:", array4.dtype, "\n")
print("Array5: 0부터 9까지 담긴 정수형 array")
array5 = np.arange(0,10)
print("데이터:", array5, "\n")
print("Array6: 0부터 1사이에 균등하게 나눠진 5개의 값이 담긴 array")
array6 = np.linspace(0,1,7)
print("데이터:", array6, "\n")
print("Array7: 0부터 10사이 랜덤한 값이 담긴 2x2 array")
array7 = np.random.randint(0,11,(2,2))
print("데이터:", array7, "\n")
if __name__ == "__main__":
main()
-
배열의 특정요소 추출
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import numpy as np
array_1 = np.array([[4,2,5],[5,3,2],[9,1,2]])
#1. 배열 array_1에 대하여 2행 3열의 원소를 추출하세요.
element_1 = array_1[1,2]
print("2행 3열의 원소는 ", element_1, " 입니다.")
#2. 배열 array_1에 대하여 3행을 추출하세요.
row_1 = array_1[2,:]
print("3행은 배열 ", row_1, " 입니다.")
#3. 배열 array_1에 대하여 2열을 추출하세요.
col_1 = array_1[:,1]
print("2열은 배열 ", col_1, " 입니다.")
#4. x의 1행과 3행을 바꾼 행렬을 만들어보세요.
y = np.array([array_1[2,:], array_1[1,:], array_1[0,:]])
print(y)
- Numpy 배열의 통계적 정보 나타내기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
import numpy as np
def main():
print(matrix_nom_var())
print(matrix_uni_std())
def matrix_nom_var():
# [[5,2,3,0], [3,4,5,1], [3,2,7,9]] 값을 갖는 A 메트릭스를 선언합니다.
A = np.array([[5,2,3,0], [3,4,5,1], [3,2,7,9]])
# 주어진 A 메트릭스의 원소의 합이 1이 되도록 표준화 (Normalization) 합니다.
A = (A - np.min(A)) / (np.max(A)-np.min(A))
print(A)
# 표준화 된 A 메트릭스의 분산을 구하여 리턴합니다.
A = np.var(A)
return A
def matrix_uni_std():
# 모든 값이 1인 4 by 4 A 메트릭스를 생성합니다.
A = np.ones((1,4,4))
print(A)
A = ((A - np.mean(A)) / np.std(A))
# 표준화 된 A 메트릭스의 분산을 구하여 리턴합니다.
return A
main()
- Numpy 함수로 행렬연산 다루기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
import numpy as np
array1 = np.array([[1,2,3], [4,5,6], [7,8,9]])
#array1의 전치 행렬을 구해보자.
transposed = np.transpose(array1)
print(transposed, '는 array1을 전치한 행렬입니다.')
#array1과 array1의 전치 행렬의 행렬곱을 구해보자.
power = np.dot(array1 , array1)
print(power,'는 array1과 array1의 전치 행렬을 행렬곱한 것입니다.')
#array1과 array1의 전치 행렬의 요소별 곱을 구해보자.
elementwise_prod = array1 * transposed
print(elementwise_prod, '는 array1과 array1의 전치행렬을 요소별로 곱한 행렬입니다.')
array2 = np.array([[2,3],[1,7]])
# array2의 역행렬을 만들어보자.
inverse_array2 = np.linalg.inv(array2)
print(inverse_array2,'는 array2의 역행렬입니다.')
# array2와 array2의 역행렬을 곱한 행렬을 만들어보자.
producted = array2 * inverse_array2
print(producted,'는 array2와 array2의 역행렬을 곱한 행렬입니다.')
Pandas
- Pandas는 데이터 분석 기능을 제공하는 라이브러리로 csv, xls 파일 등의 데이터를 읽고 원하는 데이터 형식으로 변환한다.